While it's a nearly unbearable cliche to talk about how we live in an "information age," I believe success as a leader or manager requires a deep understanding of what exactly working in an "information age" actually means. As of 2018, over 90% of the data created in the history of our species was created in just the prior two years. This has the potential to be a sea change on par with the invention of the alphabet, the printing press, or the computer, and perhaps even more so. While this has widespread implications for our political, cultural, and social systems (check out the work of Martin Gurri and Daniel Schmachtenberger for more), understanding it in a business context is a do-or-die differentiator for managers in the current environment.
THINK
Businesses as information processing systems
To explore the impact of exponential data generation on businesses, it's helpful to recognize what an organization is from an information perspective: an information processing system. Individuals as nodes in the network get various signals, both external (market data, technical data, customer data, etc.) and internal (questions, requests, promotion criteria, culture, etc.), and synthesize that information into pictures for others or actions meaningful to achieving collective goals. According to McKinsey, this information processing activity represents 61% of the average employee's work week — and the proportion is probably higher for managers and executives.
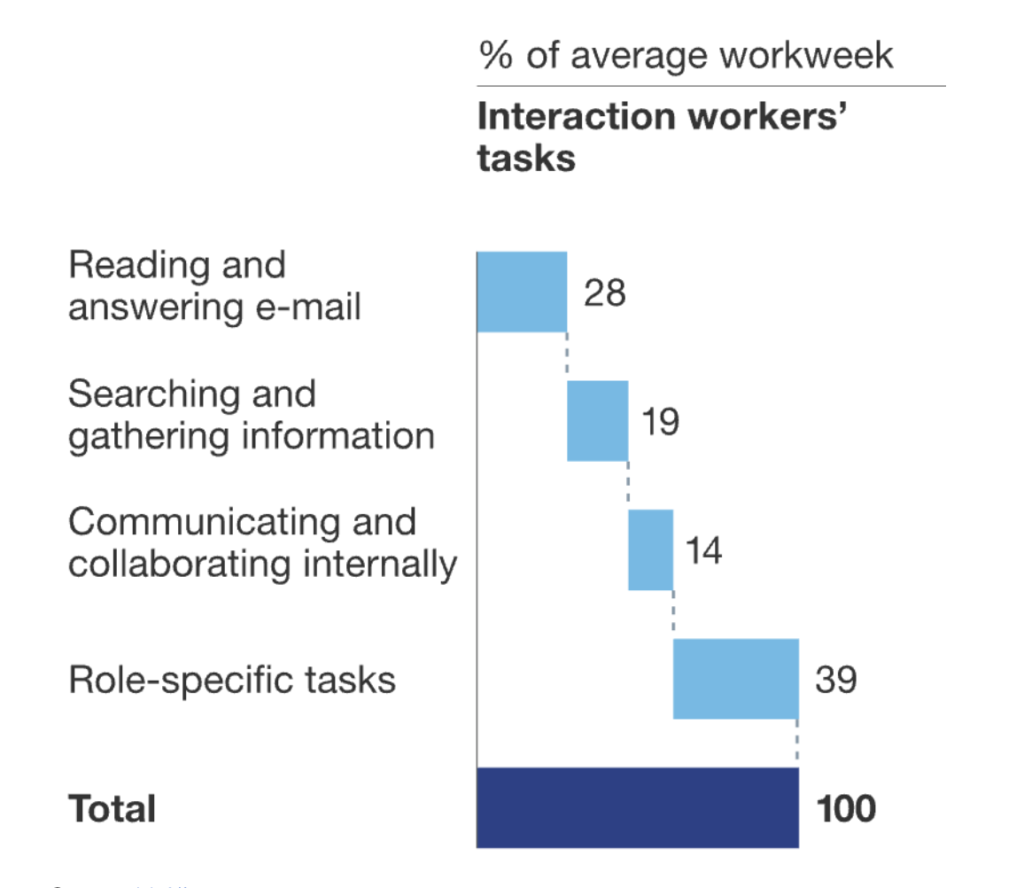
Source: McKinsey
Given the staggering amount of time modern employees devote to information processing, the quality of that activity makes a huge difference in the overall productivity of any given firm. This is where confusion comes in. For the information to actually lead to goal-relevant decisions, people need to KNOW what's relevant. In order to know what's relevant, they have to process lots of internal signals about what matters (see the enterprise clarity model) and be able to distill what matters themselves.
As information is passed between nodes, confusion and lack of alignment leads to both degradation of the signal and decreasing attention to the signals that matter. Think about what's being asked of people — to determine what's relevant to the business, to their team, and to their individual work, and align with others about that picture in a way that leads to productive action — all while the world changes around them and the information they're expected to process grows exponentially. This is especially difficult because of how the human brain experiences obtaining new information.
More information doesn't lead to better decisions without more sensemaking capacity
"The whole place just lit up. I mean, all the [alarm] lights came on. So instead of being able to tell you what went wrong, the lights were absolutely no help at all."
— Comment by one space controller in mission control after the Apollo 12 spacecraft was struck by lightning (Murray and Cox, 1989).
Data isn't all that different from energy. Just as ingesting more calories than your body can use leads to obesity and diminished physical performance, ingesting more data than you can process can lead to mental flabbiness. Yet while we've come to recognize that our calorie-rich environment is a dangerous temptation to our neolithic brains, few of us have developed a similar recognition of our natural desire to seek more information, and the cost that can have in our newly data-saturated environment.
Some early evidence suggests the saturation of data and its presentation through existing online platforms is having an impact at a neurological level, affecting everything from our ability to sustain attention, to memory and social perspective-taking. Multiple studies have shown the downsides of more data on decision making itself: it increases confidence without increasing accuracy, can lead you to anchor to irrelevant data and discard what's useful, and get stuck in analysis paralysis.
A government study on data overload from all the way back in 1998 warned of the ways in which the increasing availability of data was having a deleterious effect on employee performance in everything from space missions to intelligence gathering. The fundamental issue ultimately came down to the challenge of significance: not only that it was difficult for subjects to determine what mattered as more information poured in, but that WHAT mattered shifted depending on context, making rule-based design methods for sorting data difficult. Likewise, the availability of data from so many sources can give an illusion of competence when adequate sensemaking structures aren't in place. Sometimes this can manifest in comically inept ways. When analyzing events in Syria, the CIA was assessing rebel sentiment from English-language tweets (because the programmers who built the system found that easier to work with), when most of the communication was taking place on Facebook in Arabic.
In other cases, what's relevant gets washed out by a lack of signal differentiation. People get so many alerts that the underlying relevance gets lost in the constant buzz of new signals competing for their limited attention. Nearly everyone (especially those in management positions) has experienced the firehose of digital demands on their attention — the 300 new emails, the 57 highlighted slack channels, the dashboards of sales figures and click-through rates and employee engagement scores all claiming to be urgent over your morning coffee. Most of us sort through this barrage intuitively, unconsciously picking up on the information we find most threatening, comforting, or otherwise confirming of our existing mental models. Said differently, most of us cope with more information by deepening our existing biases and looking for patterns that fit our existing ideas of what's going on.
While many have given up on the idea of humans being able to process this exponential flow of information, AI in many ways exacerbates the underlying problem. Poor inputs and lack of clear relevance signals in a new context equals bad outputs, now further obscured in algorithmic black boxes, and the false comfort of technology we don't understand.
The failure of unprocessed data ingestion is even starker at an enterprise level
Many executives are stuck in the paradigm of information as a technological issue, rather than recognizing it as an extension of their organization's existing information processing capacity (or lack thereof). It's not all that different from implementing a CRM system like SalesForce with no reference to what the sales team is actually doing, no involvement of the sales management, and no vision for how it's going to help them achieve their goals. Perhaps unsurprisingly, an estimated 70-90% of big data projects fail.
Data scientist Michael Lukanioff gives a concrete description of how the lack of effective enterprise-level sensemaking and management leads to wasteful, failed data projects:
"Successful data science projects start with a clear vision of a specific business problem that needs to be solved and are driven forward by teams that are aligned in that vision from top to bottom. Unfortunately that's not how most data projects in the 'Big Data' era started. Instead they'd start with the construction of an all purpose data platform or 'data lake' designed to store all data from all sources, without getting into the minutia of the specific data uses. The first stop was a seemingly inexpensive HDFS file system (aka Hadoop), which seemed like cheap file storage — unless you wanted to query it — then you'd have to assemble a team of engineers, and since no one had experience with the new technology you'd have to poach them from Facebook and pay each of them more than your CFO. Once you had your data lake up and running 6–12 month later, you still needed to build a reporting layer on top of it. If you happened to be responsible for creating insights with the data through custom analyses, odds are, you were a distant afterthought and there wasn't really an access point for you in this technology stack. So you jerry-rig an export through the reporting layer into a sandbox server where you have to plead with IT to let you install Python Jupyter notebooks or an R server. Adding insult to injury, you discover that nowhere in this super-powered modern data architecture has ongoing data hygiene been contemplated, so the 'simple' data export you rigged returns the same errors with every pull and there is no protocol for correcting the upstream data. In order to overcome the shortcomings of the massive data lake that actually makes the relevant data tortuously inaccessible, your simple export becomes a separate work-stream and database with an independent ETL process written in python or R and your 'sandbox' rapidly starts to rival the master data lake in size. Since your work is still an unofficial part of the data stack, your ML code remains in your sandbox (or maybe your laptop). God help the poor sucker who tries to pick up where you left off when you leave!"
Cutting through the technical jargon, what Lukanioff describes is the massive confusion that occurs when companies seek data ingestion and storage without a commensurate investment in sensemaking capacity. Data collection becomes an end in itself, without consideration for what data matters and how it should be used in the context of the organization's existing sensemaking infrastructure (which is already diffused over the executive team, managers and HR). The result: more confusion, more waste, and worse performance than if the company had done nothing at all.
Good sensemaking capacity depends on good management and enterprise clarity
None of this is new, exactly. More than 2000 years ago, Plato had voiced concerns that the widespread introduction of writing would handicap people's ability to think and remember, with a commensurate degradation in social cohesion. While in some cases that may be true, the effective increase in coordination and the creation of entirely new paradigms such as logic and written law seems to have been well worth it. A similar story may be playing out today with big data. It's undeniable that in many instances, better access to data does lead to better decisions, from sophisticated customer targeting algorithms to AI research aids in the pharmaceutical industry. The entire approach of "growth hacking" — rigorously gathering and applying data through A/B testing to maximize marketing and product development — has been instrumental in the success of most of today's tech darlings: Twitter, Google, Facebook, YouTube, Udemy, etc.
In fact, many of the most successful companies today — Amazon, Google, Facebook — are distinguished by their ability not just to gather huge amounts of data (a common misperception), but their ability to effectively make sense of it toward their commercial goals. Amazon, for example, is relentless about pushing their operating principles to focus the data analysis back toward the underlying customer experience and weaknesses in the competition. Facebook, on the other hand, is laser-focused on increasing a small number of key indicators (like number of users and time on platform) and converting that into value for advertisers. Whatever you think of their ethics, these companies have demonstrated that success in the current environment requires an ability to not just collect and organize vast quantities of data, but to have clear sensemaking structures in place — goals, vision, management, and culture — that allow the information to be converted into effective action.
Good sensemaking hinges on the ability to merge salience (what gets attention) with relevance (what matters to achieving goals). When there's a gap between the two, we focus increasing amounts of our attention on information that's less and less relevant to our intentional goals. Good sensemaking merges the two — making the information that's relevant salient to the participants in the system. This is the job of leaders and managers. However, because almost no one is paying attention to the dynamics of confusion and clarity and their own personal mastery, we default to processing the overload of information through salience (what's loud and confirms our certainties) making what's relevant ever harder to see.
Effective organizational sensemaking capacity depends on the ability of leaders to continually create clarity for their organizations through recognition of their own blind spots, clear goal setting, clear signals about culture, clear visions for what matters and what doesn't, such that any technology implementation and data gathering is done in the context of what the organization needs to achieve. It depends on managers reimagining their roles as the frontline in organizational clarity — consistently checking for confusion, diagnosing its source, and leveraging the gap for ongoing learning about both their employees and the most effective design for achieving their goals. Going back to the frame of companies as information processing systems, good managers will be signal clarifiers, converting the inevitable degradation of information as it passes through the network into meaningful syntheses and learnings.
Clarity is the highest-value vector in a polluted information ecosystem
Combining all of this above, it looks like we're in a historical limbo similar to the time between the introduction of the printing press and the invention of the scientific method. The printing press allowed for the mass sharing of information, but without the right processing framework it just led to social upheaval. It wasn't until a better sensemaking algorithm came along that leveraged the easy trading of mass produced information that civilization realized the benefits. I think we're in a similar situation now. As businesses and political groups rush to get more and more data, I expect their performance to get worse, not better. What's needed is a new form of sensemaking — a way to determine which information matters, in what context, and how to align that sensemaking across large groups of people trying to coordinate toward shared goals in the midst of change.
Companies with the ability to effectively process more information than their competitors will be able to marshall radical leaps of insight. Problems that may have taken months of study in the past can be resolved in days, while the competition sinks more and more time and attention into areas that don't matter, exponentially widening the divide between companies that are clear and companies that are perpetually confused. In today's world, information access isn't a differentiator — clarity is.
REFLECT
- How do you currently use data within your organization?
- How has your relationship shifted over the past five years?
- How do you determine what data is relevant to the problem at hand?
TRY
- Write down your 2-3 most important goals.
- Write down the information you believe would be MOST relevant to moving forward on those goals.
- Compare that to the information you currently gather through your organization or personal efforts. How do they line up?


