Whether an organization is recruiting, raising the pay of existing workers, or promoting them to new positions, reliable indicators of current and potential employee value are required to make good business decisions. Despite this, reliable performance assessment methods have remained elusive, miring companies' success in a bog of uncertain outcomes. This paper delves into the statistical backbone of performance assessments, finding evidence of widespread disagreement and confusion. While most assessment techniques seek to either mitigate the effect of the work environment or ignore it, a fundamental and consistent flaw is the failure to truly separate context from performance. Deeper analysis reveals that context is in fact inseparable from performance — it is the thing being performed.
The Right Stuff
Jeff Smisek seemed like the perfect man for the job.
A self-described "airline geek", Smisek's 15-year run at Continental Airlines coincided with the company's transformation from a nearly bankrupt organization, structurally fractured by several mergers, into the highest-ranked U.S. airline on Fortune magazine's annual list of World's Most Admired Companies. Gordon Bethune, the CEO who originally hired Smisek away from his old law firm, claimed, "he engineered the salvation of our company."
Smisek's role in Continental's turnaround was reflected in his climb up the corporate ladder, moving rapidly from general counsel to CEO. Easygoing and well liked, his work in implementing the company's strong, positive culture was considered one of his biggest accomplishments. In 2010, when Continental merged with United to become the country's third largest airline, no one was seen as a better person to lead the new conglomerate than the man Fortune magazine dubbed "king of the skies."
Smisek was forced to resign his position in September. A man once renowned for his transparency and honesty was finally doomed when he came under federal investigation for backroom dealings with the Port Authority of New York and New Jersey. His illicit activities, aimed at getting his troubled airline a leg up rather than lining his own pockets, were the actions of a man desperately trying to give his company a competitive advantage.
But even before that his tenure at the head of United was widely considered a debacle. United's toxic labor environment did not clean up as easily as Continental's. Customer satisfaction was the lowest of the major, non-budget airlines, exacerbated by technological issues that twice forced United to shut down its fleet. The profits posted by the company were outpaced by those of its competitors. Thrown into a brewing chaos, United has now had three CEOs in the past six weeks.
In 2010, no one saw this coming. Jeff Smisek was a star.
Finding Diamonds in the Rough
Smisek and the United-Continental merger will likely provide fodder for business school case studies for many years, but the situation clearly demonstrates one truism: assessing potential performance is extraordinarily difficult. Yet challenging as it is, it remains a critical part of winning at business. Whether an organization is recruiting new employees, raising the pay of existing workers, or promoting them to new positions, reliable indicators of current and potential employee value are required to make good business decisions. This is due to another truism: the more accurate the predictors of potential performance, the more competitive advantage that can be gained from an organization's human capital.
Last spring Wired magazine published an article by Laszlo Bock, Senior Vice President of People Operations at Google, about his company's performance assessments used during the recruiting process. Bock's insights are rightly of interest to anyone invested in recruiting — his company consistently attracts top talent and is regarded as one of the best places to work, driving innovation and stock price alike. His book, Work Rules!, landed on the New York Times bestseller list.
Bock espouses a science-driven approach as the best way to predict performance. Foundational to Bock's thinking is a meta-analysis on performance assessments published in 1998 by Frank L. Schmidt and John E. Hunter. Combing through 85 years of studies on personnel selection, Schmidt and Hunter evaluate 19 separate assessment techniques for current or potential job performance.
Their analysis comes to several important conclusions. Primacy is given to General Mental Ability (GMA) tests, which evaluate how well an individual learns and solves problems. The most well known of these is the Wunderlic test, popularized by its use in the NFL scouting combine. Schmidt and Hunter's analysis demonstrates that these types of examinations are the most effective at predicting performance regardless of an employee's previous work experience or training.
In fact, because of their predictive efficacy and flexibility, Schmidt and Hunter only evaluate other techniques with respect to how much more they add to the effectiveness of GMAs. Among these, they find that integrity/conscientiousness tests show the most added value, followed closely by the use of structured interviews. Importantly, their work shows that traditional methods such as unstructured interviews and reference checks — still widely used today — are largely ineffective at predicting performance.
In his Wired article, Bock takes some minor liberties with Schmidt and Hunter's analysis — they are less enthusiastic about work sample tests than he is, since they are only applicable to highly trained job seekers. But his commitment to using the best available data to achieve higher fidelity in assessment is admirable.
However, even Google could stand to improve its methods. Despite decades of research into this problem, the actual predictive accuracy of performance assessments remains astonishingly low. Even the GMA tests that provide the bedrock for Schmidt and Hunter's analysis only have a small correlation with eventual performance (26%), standing out only relative to other, less effective methods. Google may be evaluating more effectively than their competitors, but they have only improved on a methodology that was largely ineffective to begin with.
For instance, regardless of the hiring methodology being used, one might hope that senior hiring decisions had higher levels of success than those for non-managerial positions. After all, there's more experience and indirect performance data to bolster judgements. But the reality is more bleak. According to a study by Leadership IQ, 46% percent of new senior managers fail within 18 months, while only 19% achieve unequivocal success in their new position. These odds are worse than betting your payroll on a hand of blackjack.

These failed hiring decisions likely reflect the utilization of a wide variety of performance assessment techniques, including those either supported or invalidated by Schmidt and Hunter's data. But even so, the modest improvements purportedly imparted by the GMA and its supporting techniques do not represent radical increases over a 19% success rate. Even if those techniques could double the effectiveness of hiring decisions — and there's not any indication they can — a 38% success rate is still woefully inadequate. Despite decades of study and insight, our comprehension of performance remains occluded.
What's Normal in Performance?
Clearly this problem of performance assessment isn't yet solved. Not only is it apparent that we haven't mastered it, it's difficult to claim we even understand it. We must go to the root of the problem, and reevaluate some of our basic hypotheses about the nature of human capabilities.
Reading through Schmidt and Hunter, it stands out that their analysis is based upon the assumption that work performance falls on a normal distribution — the famous bell curve that can be used to represent anything from blood pressure to the height of ocean waves. The normal distribution has many appeals — the mean is stable and easy to identify, like the top of a rolling hill. It is comparatively easy to determine the likelihood that a result will deviate from the mean, and to predict by how much. But in order to have a normal distribution, the range of above-average results needs to mirror the range of those that are below average.
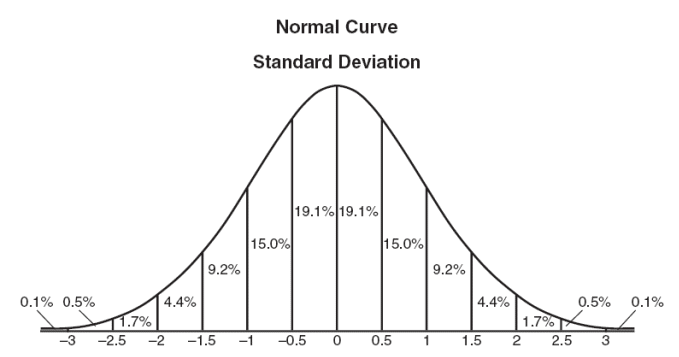
For Schmidt and Hunter and leagues of researchers like them, mean performance is stable and roughly representative of most work done. Under this assumption, roughly 68% of workers fall within one standard deviation of your average worker. At the extremes, the performance of "stars" — those rarities who truly excel in their role, the top 0.1% of performers — is offset by those workers who are as unproductive relative to the average worker as the "stars" are productive. Improving performance company-wide necessarily involves moving the entire mass of workers forward, with focus likely drawn to "bringing up the rear."
How People Stack Up
The assumption of normality in performance distribution is in need of interrogation. Common sense fails to align some of these assumptions with everyday business reality, including the diminishing of the perceived value of exceptional performers. Also, a true random sampling of performance capabilities would involve arbitrarily throwing people into low-skill job roles irrespective of their interests. But the sample is never random. All of the people being assessed are those who want a specific job, which biases the results.
Consider, for instance, the distribution of performance in professional baseball, a game that has had leagues of professionals and hobbyists analyzing its data for decades:

The population of baseball players as a whole (i.e., everyone who has ever played the game from tee-ball on up) might have a normal distribution for performance, but the distribution among professional players at the minor and major league levels lies on the far side of the graph, as seen in the image above. Since the normal distribution does not have scale invariance — that is, one cannot take any arbitrary segment of it and expect it to show the same pattern as the whole — the distribution of major and minor leaguers should in theory approximate a slope more so than a bell.
Of course, reality is a bit more messy. There are some amateurs who can perform better than the least effective athletes in the minors, and certainly minor leaguers who could best the performance of the worst major leaguers. Still, given a sampling of the world's greatest players, it would seem strange to see a normal performance curve in professional sports circles.
But this is an assumption. Luckily, baseball data are readily available. If we look at only "qualified" players — that is, those who played full time and were rarely if ever demoted — our assumptions of non-normality seem challenged (as measured by Wins Above Replacement):

The graph seems to be an amalgam. There is a rise and fall that looks superficially similar to a bell curve, but the graph tails off to the right, where the players who are consistently the best in the game are represented. Traditionally, these players are considered "outliers" and ignored in performance modeling.
However, this sample doesn't really represent the performance of all major league players, instead being biased in favor of those who were able to remain in the lineup all year long. This is influenced not only by skill, but by health, position, and contract status. If you include the results of all players who were employed on a major league baseball team at some point in the year, the shape of the curve changes, approximating to a far greater degree the slope expected from our earlier hypothesis. This graph, with its long upward proceeding tail, does not closely approximate a normal distribution, and shows the incredible production of the stars of the sport:

Sports analogies can help us understand the more abstruse world of business with greater clarity. However, there are of course many differences between working in an office and athletic contests, and the conclusions drawn from the baseball example above do not prove the normal distribution of performance to be invalid. But just as baseball players work hard to become professionals, so too do engineers, accountants, and people with myriad other occupations. Placing their performance in a radically different distribution than the major league ball players is an act that demands justification, where none is provided.
The Power of Performance
Researchers Ernest O'Boyle, Jr. and Herman Aguinis noticed this fundamental disconnect between observable data and research practices. In 2012 they published a study in Personnel Psychology attacking the assumption of a normal distribution in performance contexts.
Their introduction sheds light on a litany of problems. For one, the normality of performance distribution was assumed by other researchers from the beginning and not questioned for decades. This assumption was then not only reinforced but also systematized through the use of performance scores:
In developing a performance appraisal system, Canter (1953) used "a forced normal distribution of judgments" (p. 456) for evaluating open-ended responses. Likewise, Schultz and Siegel (1961) "forced the [performance] rater to respond on a seven-point scale and to normalize approximately the distribution of his responses" (p. 138). Thus, if a supervisor rated the performance of her subordinates and placed most of them into a single category while placing only a small minority in the top ranking, it was assumed that there was a severity bias in need of a correction to normality (Motowidlo & Borman, 1977; Schneier, 1977).
These systematically and artificially normalized performance scores were then used to assume the normality of performance, thus effectively begging the question entirely.
O'Boyle and Aguinis' takedown of these practices is damning. Even as decades of previous skepticism is described, it is made clear that no one has made a serious challenge to the reign of the bell curve. The presumptive paradigm was a stark-naked emperor all along.
Of course, a vanquished paradigm needs to replaced by something better able to make sense of the data. O'Boyle and Aguinis noted that the greatest problem with the normality assumption was its ability to deal with clear outliers that were far removed from the mean. To rectify this, they propose that performance lies on a power curve or Paretian distribution, as seen in the figure below. In five different analyses, they show how a Paretian curve fits different performance assessments far better than the bell curve.

O'Boyle and Aguinis' article has all the power and pretenses of a revolution in the way we think about performance. If their analysis is correct, Google's (and many others) normality-based methods would then not be adequately designed to identify real value. Since the greatest value comes from performers who are operating in the long tail of the curve — the "stars" of the organization — advantage is gained by those whose assessment techniques are based on Paretian models.
While it would not affect all organizations, many of whom already rely on "star power", these insights would be disruptive to a great many businesses. In a follow-up article, they detail the consequences of their star-focused conclusions:
- Nonperformance-based incentives that homogenize outputs become counterproductive — e.g., a limited scale of pay distribution, longevity-based promotion decisions.
- Downsizing is even more disastrous. It either pushes stars to leave a failing organization, or causes stars, who often have higher pay or atypical work arrangements, to become the target of elimination in a homogenizing organization.
- Old management practices, which seek to increase performance by pushing the entire distribution to the right, focus wrongly on those least likely to add significantly to outputs. Instead, the focus should be on removing ceiling constraints for stars and shifting the approach to star management and star retention.
On a deeper, though perhaps more academic level, O'Boyle and Aguinis' work also resolves a problem with finding the true value of human capital. The resource-based theory of competitive advantage concludes that winning companies are driven by resources that are valuable, rare, inimitable, and non-substitutable. The problem with human capital is that if job performance falls on a normal distribution, competent work is essentially none of those things. O'Boyle and Aguinis' analysis then potentially demonstrates a way that human capital can be a driver of competitive advantage — an organization maximizing the utilization of stars simply shines more brightly.
Stars in Focus
However, the skepticism that O'Boyle and Aguinis bring to the idea of normality ought to be applied to their own work as well. And on close inspection, the data showing the existence of a Paretian distribution in performance have their own problems.
O'Boyle and Aguinis draw their conclusions from a set of five analyses of four different fields: academia, politics, arts & entertainment, and sports. To measure success in academia, they track the number of publications in top journals in the field; for politics, electoral victories are counted (a measure so weak the authors themselves take the time to criticize it); entertainers are judged on the basis of award nominations; and athletes on the basis of career accomplishments or on-field failures. Of these four, only the last two seem to directly measure performance, with the others instead measuring response to performance.
More problematic, the analyses privilege top line thinking, with judgements based on appearing in "the best" journals, getting nominated for the most awards, being the most popular. These accomplishments will attract those who are highly motivated by such accolades. Designing organizations around such attention- and reward-seeking behavior has been shown to have problems.
What if you're not trying to beat everyone else, trying to grab the golden ring? Assessing film directors in their paper's second analysis, O'Boyle and Aguinis' methodology assigns the same level of "performance" to Sergio Leone, Jean-Luc Godard, and the director of Sharknado. And since none of them were ever nominated for an Oscar, all of them are on the left side of the Paretian distribution reserved for the masses of "poor performers".
But there is more than one way to judge success, and those judgements will be particular to the organization. The Independent Spirit Awards will have a different assessment of artistry than the Golden Globes. The New Yorker will have a different assessment of writing than VICE. Apple will have a different assessment of design than Google. Theranos will have a different assessment of research than Johnson & Johnson. Stars to one organization may not be stars to the other.
The elephant in the room is context. O'Boyle and Aguinis recognize this, and go to some lengths to dissociate performance from context by selecting metrics that the performer supposedly had control over. For three of the analyses they use in their paper, this is simply false. The peers reviewing top journals are beset by biases similar to any other human. Politicians from different parties do not play on a level playing field in gerrymandered districts. The opportunities for different film and television actors are highly influenced by age, race, and gender. All of these factors (and more) are highly indicative of the fact that performance assessments in these fields are clearly not context-independent.
Sports is a more useful analogue because performance is measured directly. Returning to baseball, we can understand playing right field and batting against an extensive variety of pitchers is relatively consistent independent of major league team, and true performance levels are easily gauged and compared. But subtle tweaks lead to disastrous results for even the biggest stars. When softball pitcher Jennie Finch faced off against the best major league players at numerous points in her career, they were helpless despite the markedly reduced velocity of the pitches and increased ball size — the major leaguers simply could not operate in a context where the ball was travelling at trajectories different from what they had trained for. In an interview with ESPN, Finch explained:
"I was throwing them mostly rise balls and change-ups. They've never seen a pitch like that, you know? With the closer distance from the mound, I think it really surprises them how fast the pitch gets there. And especially with the rise — when they're used to that over-the-top release point — there is nothing else like it. The ball movement throws them off."
Baseball is a strictly ordered set of rules and behaviors. The individual levels of performance are strongly affected by small changes to the game. If the fences were moved in 50 feet, the premium on power hitters almost evaporates. If the bases were moved 10 feet further from each other, speedsters relying on stolen bases and infield hits would become a relic of the past. And this isn't just theoretical. In 1969, home runs and walks significantly increased when the pitching mound was lowered from fifteen inches to ten inches. The game of baseball is a rigid context.
Beyond the major leaguers humbled by Jennie Finch, there are almost innumerable other examples of stars failing in new contexts. College football legends Ryan Leaf, Matt Leinart, and Reggie Bush failed to transfer their performance to the NFL, while late round afterthoughts like Joe Montana and Tom Brady became celebrated champions. In the arts, crossover albums from some of the world's most successful musical artists are generally considered curious novelties by audiences and denigrated by critics, rarely achieving a real measure of cultural impact. After his most famous work was published, Albert Einstein spent decades trying in vain to make sense of quantum mechanics. Jeff Smisek couldn't make sense of United Airlines.
Performance is Context
Rather than ignoring or mitigating context, we should seek to understand it as deeply as possible. Being able to predict how skills and performance will evolve between different jobs, departments, and companies becomes a highway to competitive advantage.
But such understanding is not easy to puzzle out. It starts with grasping some basic principles behind the transfer of learning. Any job is going to require some amount of learning from previous experiences to be used in a new context. Many types of learning produce effective memory, but poor transfer to related areas. And as demonstrated in the examples above, one of the things that noticeably inhibits transfer is highly contextualized learning.
There have been investigations of this tendency. Carraher, et al studied the use of mathematics by Brazilian street children. When making sales, they were faultlessly able — using techniques different than those taught by schools — to use addition and multiplication to deduce the final price of a combination of items (e.g., if one coconut costs 35, how much is 10 coconuts?). However, those same abilities deteriorated in a formal classroom context. Supposedly relatable word problems were significantly more difficult for them to solve, while formula-based math proved nearly unnavigable (e.g., 35 x 10 = ?). Jean Lave showed similar effects in an analysis of purchasing decisions made while grocery shopping.
In another example, there are many products in the marketplace which claim to increase cognitive performance. One of the most popular — or at least most advertised — is the online brain-training company Lumosity. But while Lumosity's memory games can be diverting and enjoyable, the evidence shows that the time spent developing skills playing their games is inapplicable to other areas. There is essentially no transfer of learning to new contexts.
These examples point to a general notion: skills are more specific and more difficult to transfer than many of us would like to believe. You can't divorce performance from context, because the context is the thing you're actually good at. While this means a star in one organization might suffer performance declines in a different environment, it also could mean that the masses huddled up against the y-axis of the power curve are simply stuck in the wrong context themselves. If that's true, that points to an incredibly powerful amount of performance potential that can be unlocked, more than can be gleaned with any traditional performance assessment.


